

VERSES' Latest Research Advances Beyond GenAI with RGM Conceptual Modeling
For Better, Faster, and Cheaper AI
- ByDenise Holt
- August 7, 2024
We’re optimistic that RGMs are a strong contender for replacing deep learning, reinforcement learning, and generative AI.” — Hari Thiruvengada, Chief Product Officer, VERSES AI
From Pixels to Planning: VERSES is Transforming Generative AI and Beyond, with Scale-Free Active Inference and the Spatial Web Protocol
A single AI model that can do everything individual GenAI models can do, plus actual learning, reasoning, and planning?
And it does it faster, using less data, less processing power, and without all the drawbacks of Deep Learning neural nets?
… It may sound too good to be true, but it’s happening right now in a very real way.
In the rapidly evolving field of artificial intelligence, new research by the team at VERSES AI, Inc. continues to push the boundaries of what is possible. Their most recent paper titled, “From Pixels to Planning: Scale-Free Active Inference,” authored by VERSES’ Chief Scientist, Dr. Karl Friston, and his colleagues, present groundbreaking advancements in Generative AI modeling using an entirely new approach called, RGM (Renormalization Generative Models), representing a better, faster, and cheaper approach to AI.
In recent benchmark tests measured against today’s popular GenAI models, RGM achieved 99.8% accuracy while using only 10% of the training data, AND it does NOT consume massive amounts of energy to get there.
But Wait… How is this possible?
Rather than merely finding and extending patterns in image pixels, video frames, or audio data like Deep Learning GenAI systems, the VERSES team demonstrates a new approach called RGM that simplifies complex systems by looking at them in an entirely different way — as multi-scale objects and concepts — seeing both the big picture and the fine details, and considering them both in the process of decision making and planning.
Explained in the VERSES press release: ‘Your brain doesn’t process and store every pixel independently; instead it “coarse-grains” patterns, objects, and relationships from a mental model of concepts — a door handle, a tree, a bicycle,” grouping things into more simpler ideas or digestible parts.
They go on to say, “RGMs break down complex data like images or sounds into simpler, compact, hierarchical components and learn to predict these components efficiently, reserving attention for the most important, informative, or unique details. For example, driving a car becomes “second nature” when we’ve mastered it well enough such that the brain is primarily looking for anomalies to our normal expectations.”
They also use an analogy of Google Maps, describing it this way, “[Google Maps] is made up of an enormous amount of data, estimated at many thousands of terabytes, yet it renders viewports in real time even as users zoom in and out to different levels of resolution. Rather than render the entire data set at once, Google Maps serves up a small portion at the appropriate level of detail. Similarly, RGMs are designed to structure and traverse data such that scale — that is, the amount, diversity, and complexity of data — is not expected to be a limiting factor.”

Today we’ll take a detailed look into what this latest research means, how it differs from current AI approaches, and we’ll examine how these breakthroughs in AI technology, alongside the Spatial Web Protocol, have the potential to transform everything from content generation to the future of human civilization, industry, and our planet.
Let’s go…
Understanding the Basics: Active Inference, State-Space, and Generative Models
“At the heart of VERSES’ research is the concept of Active Inference, a framework with origins in neuroscience and physics that describes how biological systems, including the human brain, continuously generate and refine predictions based on sensory input with the objective of becoming increasingly accurate.” — VERSES AI
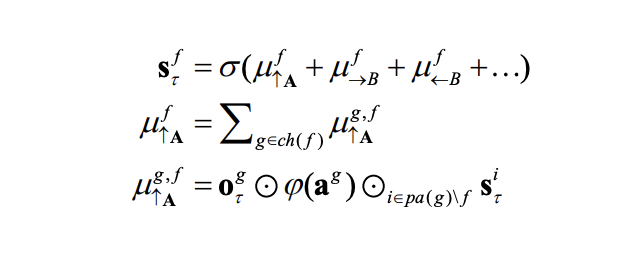
To grasp Active Inference, we first need to understand some basic concepts:
- A state-space is essentially a mathematical representation of all possible states a system can be in, along with the transitions between these states. Imagine a simple robot that can only move left or right on a straight line. Its state-space would be one-dimensional, representing its position on that line. For a more complex system like a self-driving car, the state-space would include its position, speed, direction, and possibly even factors like battery level or tire pressure. Each point in this multidimensional space represents a unique configuration of the system.

Another example would be to consider a simple weather model with states like “sunny,” “cloudy,” and “rainy.” The state-space would include these states and the probabilities of transitioning from one to another (e.g., from “sunny” to “cloudy”). This model helps in predicting future states based on current observations.

2. Active Inference, based on the Free Energy Principle, developed by world renowned neuroscientist, Dr. Karl Friston, proposes that intelligent systems, including biological brains, are constantly trying to minimize the difference between their predictions about the world (based on their internal model and understanding of reality) and what their actual sensory inputs tell them. This process of prediction and update allows the system to build and refine its understanding of the world over time.

- Active Inference is about making the best guess of what will happen next based on what you already know, then updating your guess as you get more information — like continually updating your expectations to improve your predictions.
- Active Learning is about choosing what to learn next to get the most useful information.
- Active Selection is about choosing the best option among many by comparing their predicted outcomes.
While the science behind Active Inference has been well established and is considered to be a promising alternative to state of the art AI, it previously had not yet demonstrated a viable pathway to scalable commercial solutions — until now. “
RGM’s accomplish this using a “scale-free” technique that adjusts to any scale of data.” — VERSES AI
3. Generative Models: By now we’ve all heard the term, “Generative AI,” and are familiar with Deep Learning models like ChatGPT, DALL-E, and other pixel generation, text to pixel, and large language transformer Gen AI models.

These models are used to generate new data points by learning the underlying distribution of a dataset. A generative model can create new, unseen instances that are statistically similar to the training data. For instance, a generative model trained on a dataset of handwritten digits can generate new digits that resemble the original ones.
However, this new research paper by VERSES explores an entirely new approach to Generative AI — a First Principles approach that is enabled through Active Inference, using a way to simplify models without losing important information. This helps handle large-scale problems efficiently using less data and less energy.
RGMs are more than an evolution; they’re a fundamental shift in how we think about building intelligent systems from first principles that can model space and time dimensions like we do,” said Gabriel René, CEO of VERSES. “This could be the ‘one method to rule them all’; because it enables agents that can model physics and learn the causal structure of information. We can design multimodal agents that can not only recognize objects, sounds and activities, but can also plan and make complex decisions based on that real world understanding — all from the same underlying model. This has the potential to dramatically scale AI development, expanding its capabilities, while reducing its cost.”

Key Contributions of the Research in this Paper:
· Renormalization Generative Models (RGMs): The research introduces RGMs, which generalize partially observed Markov decision processes to include paths as latent variables. This means the model can infer the underlying causes of observable outcomes over different scales and times. RGMs are especially effective in Active Inference and learning in dynamic settings.
RGMs are advanced models that help us understand and predict sequences of events by learning the hidden patterns and causes behind what we observe. They are particularly useful for making predictions in changing environments, like forecasting the next frames in a video based on the movements seen so far.

· Hierarchical and Recursive Structures: The model’s hierarchical structure allows for the recursive (repetitive/reoccurring/reiterative) generation of states and paths, akin to deep neural networks. This is significant because it enables the model to handle complex multi-scale problems efficiently. For example, in image processing, the model can understand and generate images by recognizing patterns at different hierarchical levels — from pixels to larger shapes and objects.
By processing information in layers, the model can handle very complex images without being overwhelmed by the sheer amount of data. Think of it like the ability to zoom in and and zoom out with a level of compositional understanding at every level.
· Markov Decision Processes: This is a way to make decisions where the outcome depends only on the current state, not the history. Adding paths as variables helps make better decisions over time.
· Discrete Representation: Unlike many current AI systems that work with continuous values, VERSES’ approach uses discrete states. This makes the system more interpretable and more fault-tolerant and resilient to noise and uncertainty.
A discrete state-space is a method of categorizing and defining distinct and separate states or conditions that something can be in, allowing for easier interpretation and assessment of expected outcomes and relationships. For instance, in regard to a thermostat, discrete state-spaces can be classified as “cold,” “comfortable,” or “hot.” Or in regard to healthcare, symptoms might be categorized as “none,” “mild,” “moderate,” or “severe,” and test results might be categorized into specific ranges like “low,” “normal,” “high.”
In the paper’s examples of using discrete state-spaces for image, video, or sound generation, subjects are separated and grouped into blocks, while classifying pixel intensity levels, motion states, and audio signals leveraging concepts like active inference, active learning, and minimizing variational free energy.

Using a discrete representation can simplify the model, making it more interpretable and robust, as it deals with fewer, clearer states rather than a potentially infinite number of continuous values.
This approach aligns well with the way humans often categorize and process information, making it a powerful tool for developing AI systems that need to be both effective and understandable.
· Unified Perception and Planning: The same framework seamlessly handles both recognizing patterns in sensory data and planning sequences of actions to achieve goals.
· Explicit Handling of Uncertainty: RGMs maintain probabilistic beliefs about the world, allowing them to reason under uncertainty and actively seek information when needed.
The brain is incredibly efficient at learning and adapting and the mathematics in the paper offer a proof of principle for a scale-agnostic, algorithmic approach to replicating human-like cognition in software,” — Dr. Karl Friston
Instead of conventional brute-force training on a massive number of examples, RGMs “grow” by learning about the underlying structure and hidden causes of their observations.
“The inference process itself can be cast as selecting (the right) actions that minimize the energy cost for an optimal outcome,” Friston continued
Detailed Examples and Practical Applications
“The paper describes how Renormalized Generative Models (RGMs) using Active Inference were effectively able to perform many of the fundamental learning tasks that today require individual AI models, such as object recognition, image classification, natural language processing, content generation, file compression and more. RGMs are a versatile all-in-one “universal architecture” that can be configured and reconfigured to perform any or all of the same tasks as today’s AI but with far greater efficiency.” — VERSES AI
- Image Classification and Compression: Using the MNIST (Modified National Institute of Standards and Technology) dataset of handwritten digits (a large collection of handwritten digits that is widely used for training and benchmark testing in the field of machine learning and artificial intelligence), this paper shows how RGM achieved an impressive 99.8% accuracy on a subset of the MNIST digit recognition task, a common benchmark in machine learning, using only 10,000 training images (a whopping 90% less data). The model also provides a measure of confidence in its classifications, allowing it to identify ambiguous inputs. By partitioning an image into smaller blocks and recursively applying block transformations, the model can classify and generate images with remarkable efficiency. For example, in the MNIST digit classification problem, the model groups pixels into blocks, reduces their dimensionality through singular value decomposition, and recursively builds higher-level representations. This process mirrors how the human brain recognizes patterns — from simple shapes to complex objects.

- Video and Music Generation: RGMs can model temporal sequences, making them suitable for video and music generation. By learning the patterns and transitions between frames in a video or notes in a melody, the model can generate new sequences that are coherent and contextually accurate, in an entirely new way. This capability opens up possibilities for creative applications in entertainment, such as generating realistic animations or composing music. This paper demonstrated:
- Video Compression: RGMs can efficiently compress video sequences by learning hierarchical representations of spatiotemporal (space and time) patterns. This allows for both recognition and generation of complex dynamic scenes.
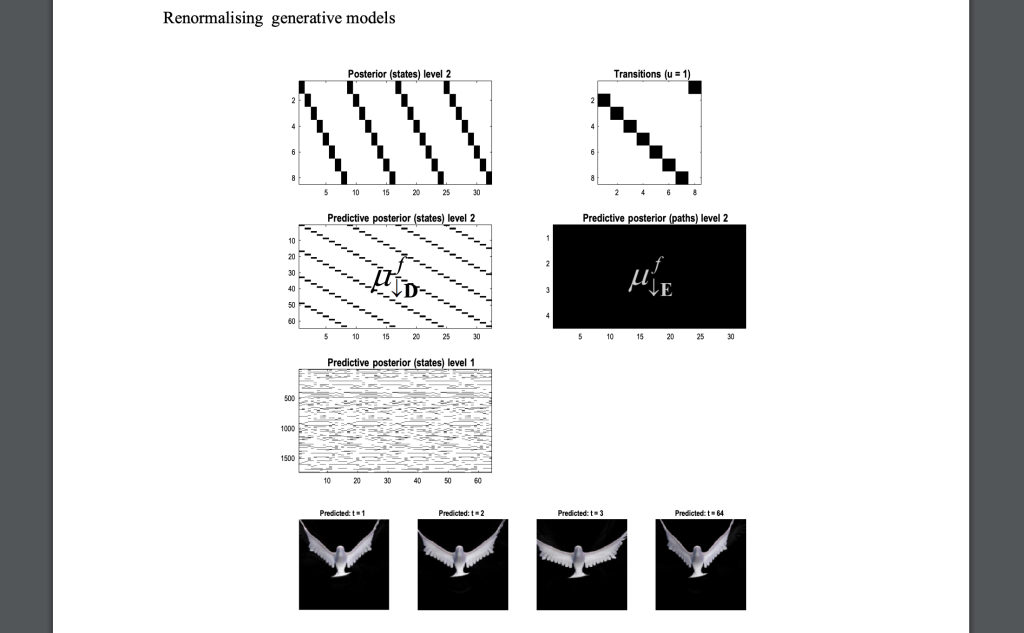
2. Audio Processing: Applied to birdsong and music, RGMs exhibit an ability to learn and generate structured audio sequences, capturing both local patterns and long-range dependencies.
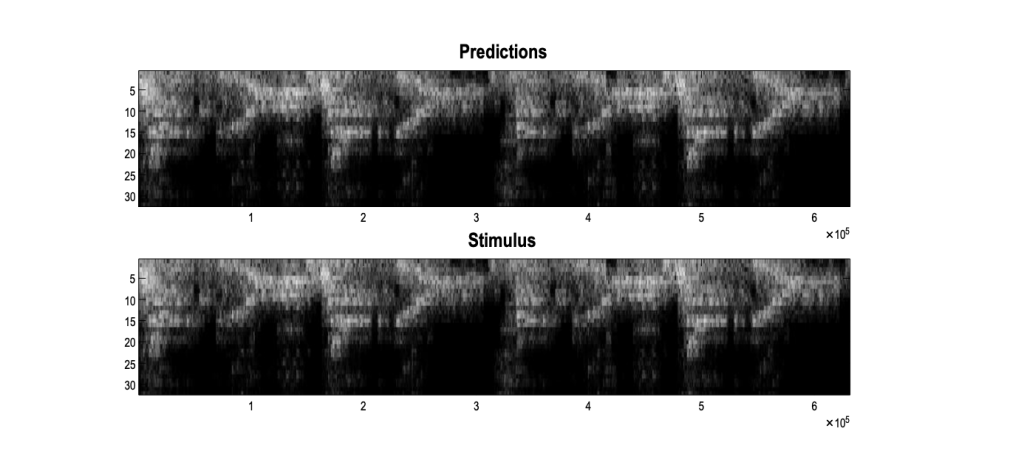
- Game Play: In simple Atari-like games, RGMs rapidly learn effective strategies through a process of “planning as inference,” showcasing how the same framework used for perception can be applied to decision-making and control. By learning the game’s dynamics and possible states, the model can plan optimal actions to achieve high scores. This application highlights the potential of RGMs in developing intelligent agents capable of strategic thinking and decision-making.
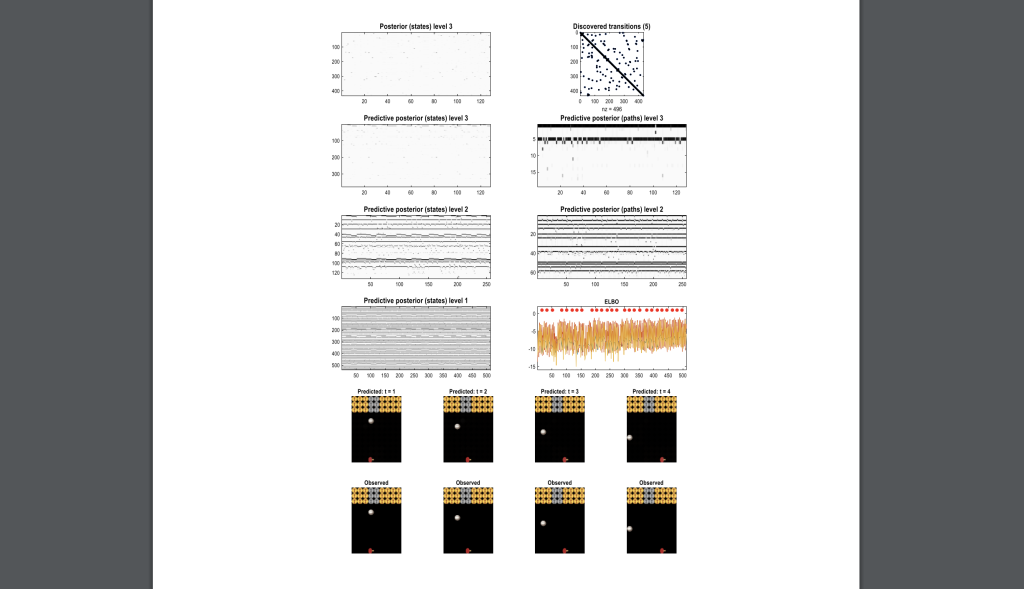
What Sets VERSES' Approach Apart
VERSES' new research introduces several key innovations:
1. Scale-free modeling: The paper describes a method for creating state-space models that can be applied at different scales, from individual pixels in an image to high-level planning and decision-making. This is a significant departure from traditional deep learning approaches, which often struggle to bridge low-level perception with high-level reasoning.
2. Renormalization: Borrowing concepts from physics, VERSES introduces a “renormalization” technique that allows the model to efficiently represent information at different levels of conceptualization. This is akin to how humans can think about the world at different scales — from individual objects to entire systems — without getting bogged down in unnecessary details.
3. Discrete representation: Unlike many current AI systems that work with continuous values, VERSES’ approach uses discrete states. This makes the system more interpretable and potentially more resilient to noise and uncertainty.
4. Hierarchical structure: The model naturally forms a hierarchy, with higher levels representing more general concepts and plans. This mirrors the structure believed to exist in the human brain and allows for more sophisticated reasoning and planning.
5. Fast structure learning: RGMs can rapidly infer the structure of their internal models from small amounts of data, rather than requiring a fixed architecture and massive datasets for training.
6. Unified perception and planning: The same framework seamlessly handles both recognizing patterns in sensory data and planning sequences of actions to achieve goals.
7. Explicit handling of uncertainty: RGMs maintain probabilistic beliefs about the world, allowing them to reason under uncertainty and actively seek information when needed.
Side by Side Comparison: Deep Learning Generative AI to RGM
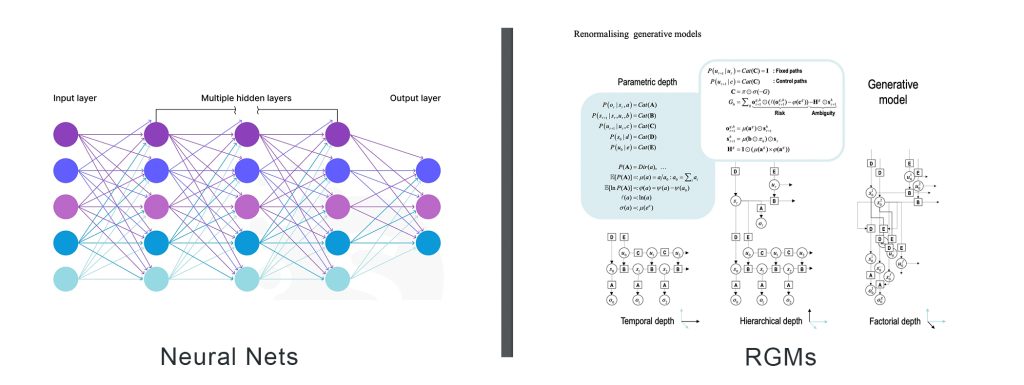
Let’s compare how Renormalization Generative Models (RGMs) through Active Inference differ from traditional Deep Learning approaches in handling the given applications: image classification, video compression, audio processing, and game playing.
1. Image Classification:
Deep Learning Neural Nets:
- Large Training Data: Deep learning models like Convolutional Neural Networks (CNNs) often require extensive training data to achieve high accuracy. They learn patterns through multiple layers, each capturing increasingly complex features.
- — -Example: A CNN needs thousands of labeled images to learn the features of each digit in the MNIST dataset, processing millions of pixel relationships to achieve high accuracy.
- Black Box Nature: While CNNs can be highly accurate, they usually do not provide explicit measures of confidence, making it harder to understand and trust their decisions.
- — -Example: A CNN might classify a digit as ‘8’ with high accuracy but does not typically indicate how confident it is about this classification, making it harder to trust in critical applications.
- Overall: CNNs process MNIST digits by learning single scale subsequent hierarchical features and need a large and extensively labeled dataset to learn the parameters of each layer and generalize well to new, unseen examples.
RGMs:
- Minimal Training Data: RGMs achieve high accuracy with less training data by efficiently inferring hierarchical representations and recognizing patterns at different scales.
- —- Example: On the MNIST dataset, an RGM might classify digits accurately by first identifying simple features like edges and curves in smaller pixel blocks, and then combining these features to recognize the entire digit, even with a smaller training set.
- Confidence Measures: RGMs provide a measure of confidence in their classifications, helping identify ambiguous inputs, which can be crucial for tasks requiring high reliability.
- — -Example: If an RGM is unsure whether a digit is a ‘3’ or an ‘8’, it can indicate low confidence in its prediction, prompting further analysis or human intervention.
- Overall: On the MNIST dataset, RGMs can classify digits accurately, identifying key features and hierarchically building from basic to complex patterns by using discrete state-spaces (pixels and blocks with intensity states) which are implemented to categorize and classify handwritten digits efficiently, leveraging concepts like Active Inference, Active Learning, and minimizing variational free energy.
While both neural networks and RGMs utilize hierarchical learning, neural nets build this hierarchy through layered feature extraction requiring extensive data and computation. In contrast, RGMs use a structured, scale-invariant approach to recognize and infer patterns hierarchically, achieving similar or better results with less data and computational resources.
2. Video Compression:
Deep Learning Neural Nets:
- Recurrent Layers: Deep learning models for video compression, such as those using Recurrent Neural Networks (RNNs) or Long Short-Term Memory (LSTM) networks, rely on learning temporal dependencies in sequences.
- — -Example: An LSTM-based model processes each frame of the video sequentially, learning to predict the next frame based on previous frames, which requires significant processing power.
- Resource Intensive: These models typically require significant computational resources and large datasets to learn and generate video sequences effectively.
- — -Example: Training an LSTM model for video compression requires processing thousands of frames and learning the dependencies between them, consuming a lot of memory and processing power.
RGMs:
- Hierarchical Representations: RGMs compress video sequences by learning spatiotemporal patterns hierarchically, recognizing and encoding patterns in both space (frames) and time (sequence of frames).
- — -Example: An RGM might compress a video by first identifying repeating patterns in individual frames (e.g., background elements) and then recognizing common sequences of these frames (e.g., a person walking), resulting in efficient storage.
- Efficiency: The hierarchical approach makes RGMs efficient, needing less computational power and data to perform compression effectively.
- — -Example: An RGM could compress a video of a person running by storing the running motion pattern once and reusing it, instead of storing every frame individually.
3. Audio Processing:
Deep Learning Neural Nets:
- Sequential Modeling: Deep learning models, such as RNNs or LSTM networks, are used for audio processing by learning sequences and dependencies in audio data.
- — -Example: An LSTM network learns to predict the next note in a piece of music by analyzing the sequence of previous notes, requiring a large amount of training data to capture all the variations.
- Training Requirements: These models require large amounts of training data and extensive computational resources to accurately capture and generate audio sequences.
- — -Example: Training an LSTM to generate coherent music might involve processing thousands of hours of audio to learn the complex dependencies between notes and rhythms.
RGMs:
- Pattern Recognition: RGMs can learn and generate structured audio sequences by capturing local patterns (e.g., notes in music) and long-range dependencies (e.g., melody or rhythm).
- — -Example: An RGM might generate a birdsong by first recognizing short chirps and then understanding how these chirps combine into longer phrases and patterns.
- Versatility: The ability to handle both short-term and long-term patterns makes RGMs versatile in processing various audio types.
- — -Example: An RGM could process speech by recognizing phonemes (short-term patterns) and combining them into words and sentences (long-term patterns). RGMs can generate coherent birdsong by learning the hierarchical structure of the song’s patterns.
4. Game Play
Deep Learning Neural Nets:
- Reinforcement Learning: Deep learning models for game playing, such as those using reinforcement learning, learn strategies by maximizing rewards through trial and error.
- — -Example: A reinforcement learning model might learn to play “Pong” by playing thousands of games, gradually improving its strategy by adjusting its actions based on rewards received for successful moves.
- Data and Compute Intensive: These models often require extensive training data (many game simulations) and significant computational resources to learn optimal strategies.
- — -Example: Training a reinforcement learning model for “Space Invaders” involves running countless game simulations, each requiring substantial computational power and time to converge on an optimal strategy.
RGMs:
- Planning as Inference: RGMs apply the same framework used for perception to decision-making, enabling the model to plan effective strategies by inferring the best actions from observed states.
- — -Example: An RGM playing “Pong” might quickly learn to position the paddle by recognizing the ball’s trajectory and planning the optimal moves to hit the ball back.
- Rapid Learning: RGMs can quickly learn effective strategies in simple Atari-like games by efficiently recognizing patterns and making decisions based on inferred outcomes.
- — -Example: An RGM could learn to play a game like “Space Invaders” by identifying enemy movement patterns and planning shots to maximize score with fewer training sessions.
Overall, RGMs demonstrate profound improvements over Deep Learning Neural Nets through:
- Data Efficiency: RGMs require less training data compared to deep learning models, making them more efficient and faster to train.
- Interpretable Confidence: RGMs provide measures of confidence in their predictions, adding transparency and reliability.
- Hierarchical Processing: RGMs handle multi-scale problems efficiently through hierarchical representations, capturing both fine and broad patterns and concepts simultaneously.
In contrast to Deep Learning, VERSES’ Active Inference approach aims to build systems that form genuine understandings of their environment, can learn efficiently from limited data, make interpretable decisions, and reason across different levels of abstraction.
The Spatial Web Protocol: Enabling a New Era of AI
VERSES’ research becomes even more powerful when considered alongside the Spatial Web Protocol. This protocol aims to create a standardized way for different technologies and AI systems to interact and share information across programmable spaces within our global internet.

The combination of scale-free Active Inference models with the Spatial Web Protocol would enable:
1. Interoperable AI systems: Different Active Inference Intelligent Agents and autonomous systems could communicate and collaborate, sharing their understandings of the world.
2. Seamless integration of physical and digital: AI would more easily bridge the gap between digital data and physical reality, enabling more sophisticated Internet of Things (IoT) applications.
3. Context-aware computing: AI systems could adapt their behavior based on a rich understanding of their current context, from physical location to user preferences.
4. Energy efficient distributed intelligence: Instead of relying on centralized, energy-intensive data centers, intelligence could be distributed across networks of smaller, more efficient devices.
The Spatial Web: A Holonic Network
The Spatial Web Protocol, designed as a nested ecosystem similar to holon architecture, provides the perfect complement to VERSES’ Active Inference AI methodology. It creates a framework where each node in the network (whether a domain, a device, an AI agent, or a subsystem) can function as a holon — autonomous yet interconnected. This alignment becomes particularly significant when we consider how Active Inference AI and the Spatial Web Protocol work together to create sophisticated, adaptive systems at various scales.
Understanding Holon Architecture
A “holon,” a term coined by Arthur Koestler, refers to an entity that is simultaneously a whole and a part of a larger system. Think of this in terms of how the human body is structured. Each cell is a whole cell, yet each cell is part of a bigger entity — an organ. Each organ is a whole organ, yet part of a larger entity — the body. Each entity is capable of functioning independently and as part of a larger system, governed by the larger entity that contains it.
In the context of system architecture, holon architecture creates a hierarchical structure of self-reliant units that each can operate as an independent entity but also serves as a part of a larger organism — reliant on the larger system that it is part of — for support and context. This concept dovetails perfectly with VERSES’ scale-free approach to Active Inference AI and the design principles of the Spatial Web Protocol.
Markov Blankets
Markov blankets define the boundary of a system, distinguishing between internal states and external influences. In RGMs, Markov blankets help isolate the different levels of the hierarchy, ensuring that each level can function independently while being part of the larger model.
By enabling scale-free modeling and interoperability, RGMs ensure that various systems — from smart city infrastructure to global supply chains — can function cohesively and adaptively, crucial for maintaining the homeostasis of complex systems.
How Do These Principles Apply to VERSES' Research?
· Recursivity: The scale-free models described in VERSES’ research naturally form a nested hierarchy, much like holons. Each level of abstraction in the model can be seen as a holon — complete in itself, yet part of a larger whole.
· Autonomy and Cooperation: Active Inference Agents, as described in VERSES’ framework, exhibit both autonomy in their decision-making and the ability to cooperate with other Agents. This mirrors the dual nature of holons.
· Self-organization: The renormalization technique introduced in the paper allows the system to dynamically organize information at different levels of conceptualization, akin to the self-organizing nature of holonic systems.
Within Genius™, developers will be able to create a variety of composable RGM agents with diverse skills that can be fitted to any sized problem space, from a single room to an entire supply network, all from a single architecture.” — Hari Thiruvengada, VERSES Chief Product Officer.
Further validation of the findings in the paper is required and expected to be presented in future papers slated for publication this year.
VERSES' Position in the AI Landscape
This latest research positions VERSES at the forefront of an entirely new and transformative approach to AI. While tech giants like Google, Microsoft, and OpenAI are largely focused on scaling up existing Deep Learning approaches, VERSES is charting a fundamentally different path.
VERSES possesses the very real potential to lead the way in developing AI systems that are more efficient, interpretable, and capable of the kind of general and potential super intelligence that has long been the holy grail of AI research. Their approach aligns well with growing concerns about AI safety and ethics, as it offers more transparent and controllable AI systems.
The Technological Convergence Across the Spatial Web

Interoperability and Integration
The Spatial Web Protocol, HSTP (Hyperspace Transaction Protocol) and HSML (Hyperspace Modeling Language) facilitates the seamless interoperability of all legacy, current, and emerging technologies across the global internet network. HSML as a common language enabling computable context, becomes the bridge of interoperability between autonomous systems, Internet of Things (IoT), Distributed Ledger Technology, AR, VR, and more, enabling different systems and devices to communicate and work together efficiently from wherever they are within the network.
Implications for Future Systems: Transforming Industries and Society
The combination of Active Inference AI and the Spatial Web Protocol are anticipated to revolutionize the design and operation of complex systems at every scale, revolutionizing entire industries:
1. Smart City Infrastructure: Cities could be modeled as nested holons, from individual smart devices to neighborhood systems to citywide networks. Each level would have its own decision-making capacity while contributing to higher-level goals. For example, a smart traffic system could optimize local traffic flow autonomously while also feeding into and responding to city-wide transportation strategies.
2. Global Supply Chains: Supply chains and production processes would be optimized with an unprecedented level of detail and adaptability, representing different scales (e.g., individual products, shipments, warehouses, regional distribution networks). This structure would allow for both localized optimization and global coordination. Through the real-time planning and adaptability of an Active Inference AI system, Intelligent Agents could predict and respond to disruptions at any level, automatically adjusting the entire chain.
3. Personal to Critical Systems Homeostasis: The holonic nature of this architecture allows for seamless scaling from personal devices to critical infrastructure. Your smartphone, acting as a personal holon, could interface with your smart home system, which in turn connects to neighborhood and city-level systems. This creates a continuum of intelligent, adaptive systems maintaining homeostasis at each level.
4. Education: Adaptive learning systems could provide truly personalized education, adjusting not just content but teaching methods based on a deep understanding of each student’s learning process.
5. Healthcare Systems: From personal wearables to hospital systems to national health networks, this new framework of distributed multi-scale intelligence would integrate data from wearables, medical records, and real-time sensors to provide personalized health recommendations, enable early disease detection and manage resources across multiple scales. It could simultaneously optimize individual treatment plans while also informing broader public health strategies.
6. Environmental Management: Ecological systems, inherently hierarchical and complex, could be modeled and managed more effectively, aiding in climate change mitigation efforts. From individual habitats to global systems, VERSES’ approach would help balance local interventions with global environmental goals.
Implications for the Future of AI and Human Civilization
The development of Renormalization Generative Models (RGMs) within the scope of Active Inference and the Spatial Web, promise to have far-reaching implications:
1. More Adaptive AI: Systems based on these principles would be much more flexible and adaptive, able to learn and operate in novel environments with minimal prior training.
2. Efficient Edge Computing: The computational efficiency of RGMs would enable the distribution of more powerful AI to run on edge devices like smartphones or IoT sensors, reducing reliance on large data centers.
3. Improved Human-AI Interaction: By maintaining explicit models of uncertainty and actively seeking information, these systems could interact more naturally with humans, asking for clarification when needed.
4. Safer AI Systems: The ability to recognize novel or ambiguous situations would lead to autonomous systems that are more reliable and fail gracefully when confronted with scenarios outside their training. When an autonomous system encounters a situation it wasn’t explicitly trained to handle, it can manage the situation in a safe and controlled manner rather than causing a catastrophic failure.
5. Accelerated Scientific Discovery: Applied to scientific domains, like genomics, climate science, drug discovery, and astronomy, RGMs could help researchers by more quickly identifying patterns and suggesting plausible explanations or hypotheses for observed phenomena and complex datasets, guiding further research and experimentation.

The research presented in VERSES’ new paper, “From Pixels to Planning: Scale-Free Active Inference,” demonstrates groundbreaking advancements in generative modeling through Active Inference AI. By combining the biologically-inspired framework of Active Inference with innovative computational techniques like RGMs, and the distributed networking power of the Spatial Web Protocol, VERSES is laying the groundwork for decentralized and distributed intelligence that would be more capable, efficient, and aligned with human values than current AI approaches.
As we move forward, the convergence of these technologies will usher in a new era of intelligent autonomous systems that are more efficient, adaptable, and capable of addressing everything from day-to-day Generative AI use cases to providing solutions for complex global challenges.
The future of AI is not just about advanced algorithms and neural networks, but about creating a harmonious and interconnected world where technology works seamlessly with human needs and aspirations.
VERSES’ role in pioneering these new developments cements their position as a leader in the field of AI and future technologies, driving progress and paving the way forward to this exciting future. As this technology develops, it has the potential to reshape not just the AI landscape, but the very fabric of human civilization, global industry, and our planet.
Explore the future of Active Inference AI with me, and gain insights into this revolutionary approach and groundbreaking research!
Ready to learn more? Join my Substack Channel for the Ultimate Resource Guide for Active Inference AI, and to gain access to my exclusive Learning Lab LIVE sessions.
Visit my blog at https://deniseholt.us/, and Subscribe to my Spatial Web AI Podcast on YouTube, Spotify, and more. Subscribe to my newsletter on LinkedIn.

Join my Substack Channel
Substack is where our community thrives!
Become a paid member, and join us for Learning Lab LIVE!
Join the conversation of this cutting edge, safe, and trustworthy new approach to AI.