

VERSES AI Leads Active Inference Breakthrough in Robotics
- ByDenise Holt
- August 13, 2025
Moving From 'Tools' to Teammates Who "Think With Us."
We’ve all worked with someone who could follow instructions but couldn’t adapt when things changed. We even have a derogatory term to describe a person like this: a tool — - dependable perhaps, but narrow, rigid, and ultimately more work for the rest of the team.
A partner, on the other hand, thinks with you. They anticipate. They adapt. They contribute reasoning to the shared mission.
Today’s robots, for all their mechanical precision, have largely fallen into this category: they are powerful tools, yet, they are still tools. They have no agency. They can follow a pre-scripted sequence of movements, but if the environment changes unexpectedly – a box is out of place, a new obstacle appears, the lighting shifts – they get confused, fail, or require extensive retraining.
If an agent or member of a team (whether human or machine) has:
- No ability to reason about context
- No flexibility to adapt plans
- No way to integrate others’ perspectives into its own model
… then they are not a true “agent.” They can only operate in a narrow lane. They might execute their specific part fine, but they’re useless (and sometimes dangerous) when conditions change. Robots like this require constant human micromanagement. In unpredictable environments, this isn’t just inefficient – it’s unsafe.
What we really need are partners – robotic teammates with agency that can read the situation, adapt in real time, and reason about the mission alongside us.

And now, for the first time, recent research from VERSES AI has shattered that barrier through Active Inference.
Advancing Robotics Through Neuroscience: Doing What's Never Been Done Before

A new paper quietly dropped on July 23, 2025, titled, “Mobile Manipulation with Active Inference for Long-Horizon Rearrangement Tasks.” In it, the VERSES AI research team, led by world-renowned neuroscientist, Dr. Karl Friston, demonstrates the blueprint for a new robotics control stack that achieves what has never been possible before: an inner-reasoning architecture of multiple active inference agents within a single robot body — working together for whole-body control to adapt and learn in real-time in unfamiliar environments. This hierarchical, multi-agent Active Inference framework enables robots to adapt in real time, plan over long sequences, and recover from unexpected problems, all without retraining.
Unlike current robots, which operate as one monolithic controller, this new blueprint operates as a network of collective intelligent agents, each powered by Active Inference – where every joint, every limb, every movement controller is itself an Active Inference agent with its own local understanding of the world, all coordinating together under a higher-level Active Inference model – the robot.
Think of it as a miniature society of decision-makers living inside a single robot’s body:
- Joint-Level Agents – Each joint (e.g., elbow, wrist, wheel) predicting and controling its movement based on sensory feedback, adjusting instantly if there’s resistance or slippage.
- Limb-Level Agents – Coordinating across joints to achieve coherent limb movement (like a full arm reaching or a base moving).
- Whole-Body Agent – Integrating multiple limbs and navigation to perform coordinated skills (e.g., reach-and-grasp while moving).
- High-Level Planner – Selecting which skill to perform next, based on the current goal and environment.
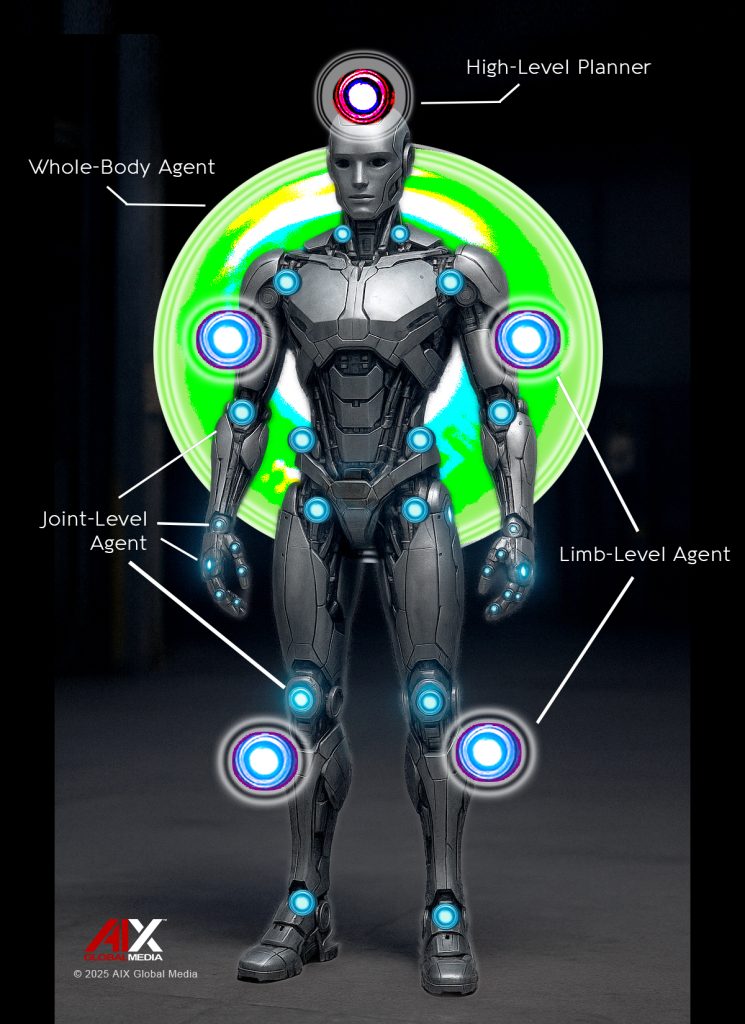
Lower-level agents handle precise control (like moving a gripper), while higher-level agents plan sequences of actions to achieve goals.
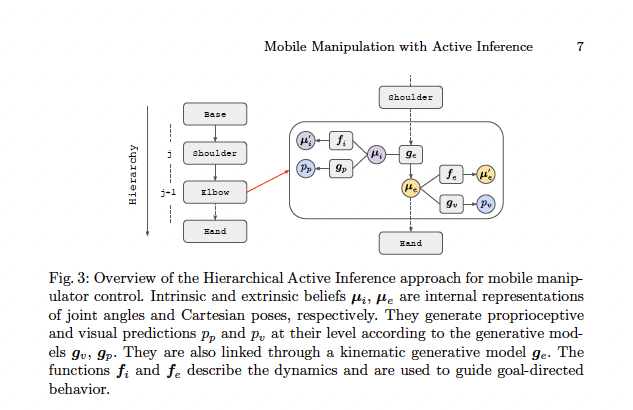
Each agent maintains intrinsic beliefs (about its own state) and extrinsic beliefs (about its relation to the world).
These agents continuously share belief updates and prediction errors:
- If one joint encounters unexpected resistance, the information cascades upward, and the high-level plan adjusts in milliseconds.
- No hard-coded recovery script is needed – the adjustment emerges naturally in the moment from the Active Inference process.
In effect, the robot is a complex adaptive system of collective intelligence – much like a human body’s coordination between muscles, reflexes, and conscious planning.
All of these agents working together within the robot are able to communicate continuously, updating their beliefs based on Chief Scientist Dr. Karl Friston’s Free Energy Principle – the same mathematical framework that underlies human perception, learning, and action. These Active Inference agents within the robot body share with each other their belief states about the world and continually update their actions based on prediction errors. This is the same process humans use when walking across a crowded room carrying coffee: constant micro-adjustments at the joint level, limb coordination for balance, and high-level planning for navigation.
This means these Active Inference robots don’t just execute pre-programmed actions, they perceive, predict, and plan in concert, dynamically adjusting instantly if the world doesn’t match their expectations. That’s something reinforcement learning (RL) robots simply can’t do, as every adjustment requires extensive retraining.
This is not just an upgrade to robotics.
It’s a redefinition of what a robot is.
AXIOM and VBGS: The Power Under the Hood
This breakthrough doesn’t stand alone – it’s built on two other major VERSES innovations:

AXIOM: A new scale-free Active Inference architecture that unifies perception, planning, and control in a single generative model.
- Joint-level agents and high-level strategic planners use the same reasoning framework.
- This makes human input naturally compatible with machine reasoning.
VBGS (Variational Bayes Gaussian Splatting): A probabilistic, “uncertainty-aware” method for building high-fidelity 3D maps from sensor data.
- Robots can represent their environment as a belief map – and share it with humans via HSML.
- Uncertainty is explicit, making collaborative planning safer and more transparent.
Together, AXIOM and VBGS give Active Inference robots both brains and senses tuned for real-time teaming.
Let's Dive Deeper…
What Do We Actually Need Robots to Do?

- Operate safely in dynamic, cluttered, human spaces.
- Plan not just the next move, but the next dozen, and change course if needed.
- Communicate their reasoning and what they know and don’t know to humans.
- Generalize across layouts, objects, and conditions without weeks of retraining.
Until now, the field of robotics has struggled to meet this standard. Most control systems are either:
- Rigidly pre-programmed – efficient only in narrow, predictable tasks, or
- Data-hungry deep learning systems – capable but brittle, requiring vast amounts of labeled training data and still prone to failure when the real world doesn’t match the training set.
Why Reinforcement Learning (RL) Robots Struggle (and Why it Matters)

Reinforcement Learning (RL) has driven impressive demos, but it hits walls in the real world:
- Massive Training Requirements: RL agents often require millions of trial-and-error interactions in simulation to master a task. That’s fine for a single fixed task, but impossible to scale for every variation a robot might encounter in the real world.
- Poor Generalization: Train a RL robot to stack red blocks in one room, and it won’t necessarily stack blue blocks in another without retraining. The knowledge doesn’t generalize well to changes in color, shape, lighting, or layout.
- Brittleness to Change: RL policies are optimized for the exact conditions of their training. A small shift — a new obstacle, a slightly different object size — can cause catastrophic failure.
- Rigid, Non‑Adaptive Body Control: RL stacks do not host reasoning agents at each degree of freedom (DoF). Control at individual joints/actuators is pre‑programmed for the task/environment it was trained on. If the environment changes (heavier object, slick floor, drawer jams, door swings wider), you must meticulously retrain the movement stack, from low‑level controllers through mid‑level skills, so hand‑offs don’t fail.
- No Built-In Uncertainty Awareness: RL agents act as if their internal model is always correct. They don’t explicitly track what they don’t know, which makes safe adaptation difficult.
- Inefficiency in Long-Horizon Tasks: When a task requires multiple steps over a long sequence (like setting a table or rearranging a room), RL struggles with planning and sequencing without breaking it down into smaller, heavily pre-trained modules.
The result? Reinforcement Learning robots are powerful tools that may shine in lab benchmarks for fixed contexts, but in a real-world setting like a warehouse, hospital, or disaster zone, they’re too rigid and brittle to be trusted as independent operators, and they are expensive to retune at every new variation.
The Inherent Logic in Active Inference
In Active Inference, logic isn’t bolted on after-the-fact as a “rule set” – it emerges naturally from:
- The generative model – which encodes the agent’s beliefs/understandings about how the world works.
- The priors and constraints in that model – which act like “rules of the game.”
- Continuous prediction–correction cycles – which maintain internal consistency and adapt reasoning to real conditions.
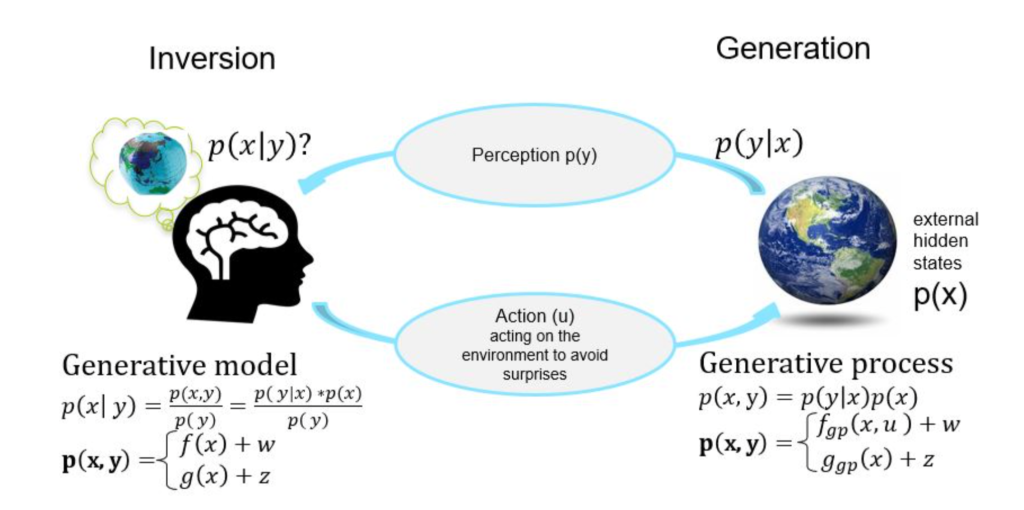
That means logic here is probabilistic and contextual:
- The agent is constantly checking: “Does this action or belief make sense given what I expect?”
- If not, it adjusts, much like a human who rethinks a decision when new evidence arrives.
The Active Inference Breakthrough
VERSES’ new research changes the game for robotics.
Instead of a single, monolithic Reinforcement Learning (RL) policy, their architecture creates a hierarchy of intelligent agents inside the robot, each running on the principles of Active Inference and the Free Energy Principle for seamless learning and adaptation in real-time.
Here’s what’s different:
- Agents at Every Scale – Every joint in the robot’s body has its own “local” agent, capable of reasoning and adapting in real time. These feed into limb-level agents (e.g., arm, gripper, mobile base), which in turn feed into a whole-body agent that coordinates movement. Above that sits a high-level planner that sequences multi-step tasks.
- Real-Time Adaptation – If one joint experiences unexpected resistance, the local agent adjusts instantly, while the limb-level and whole-body agents adapt the rest of the motion seamlessly — without halting the task.
- Skill Composition – The robot can combine previously learned skills in new ways, enabling it to improvise when faced with novel tasks or environments.
- Built-In Uncertainty Tracking – Active Inference agents model what they don’t know, enabling safer, more cautious behavior in unfamiliar situations.
The result is a system that can walk into an environment it has never seen before, understand the task, and execute it — adapting continuously as conditions change.
A Closer Look at a Robot Made of Agents
What we are talking about is a complex adaptive system that reasons at every scale of the body.
- Joint‑level agents (per DoF/degrees of freedom): maintain intrinsic beliefs (their angles/velocities) and extrinsic beliefs (pose in space). They predict sensory outcomes and minimize prediction error (differences between expected and observed proprioception/vision) moment to moment.
This mimics the human body’s sense of its position and movement in space; the ability to move without conscious thoughts, like walking without looking at our feet. This sense relies on sensory receptors in muscles, joints, and tendons that send information to the brain about body position and movement.
- Limb‑level agents (arm, gripper, base): integrate joint beliefs, set Cartesian goals and constraints (e.g., reach trajectory, grasp pose, base heading) and negotiate with joints via top‑down priors and bottom‑up errors.
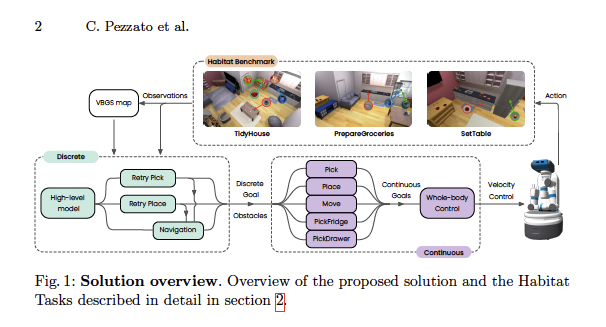
- Whole‑body agent: composes skills (Pick, Place, Move, PickFromFridge/Drawer), achieving simultaneous navigation and manipulation, with collision avoidance.
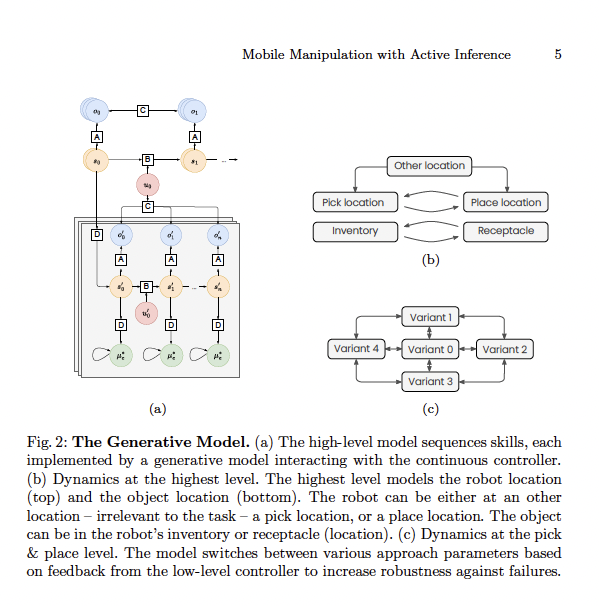
- High‑level planner: reasons over discrete task states (e.g., object in inventory vs. in container; robot at pick vs. place location), sequences skills, and retries with alternative approach parameters when failures are detected, all with no offline retraining.
How It Works (Intuitively):
Every level runs the same principle: minimize free energy by aligning predictions with sensations and goals.
Top‑down: higher agents send preferences/goals (priors) to lower ones.
Bottom‑up: lower agents send prediction errors upward when reality deviates.
This circular flow yields real‑time adaptation: if the wrist feels unexpected torque, the arm adjusts, the base repositions for leverage, and the planner switches to an alternate grasp — without halting or reprogramming.
Base–arm coupling: The base isn’t a separate “navigation mode.” Its free‑energy minimization includes arm prediction errors, so the robot walks its body to help the arm (extending reach, improving approach geometry). That’s how you get whole‑body manipulation.
Perception that Learns as It Moves: Variational Bayes Gaussian Splatting (VBGS)
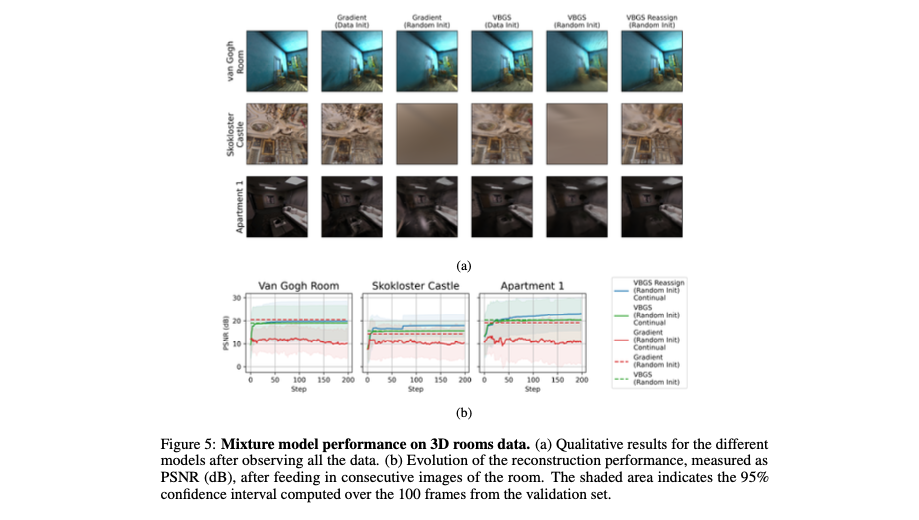
Robots need a world model that updates online without forgetting. VBGS provides that by:
Representing the scene as a mixture of Gaussians over 3D position + color (a probabilistic radiance/occupancy field).
Learning by closed‑form variational Bayes updates (CAVI with conjugate priors), so it can ingest streamed RGB‑D without replay buffers or backprop.
Maintaining uncertainty for every component – perfect for risk‑aware planning and obstacle avoidance.
Including a component reassignment heuristic to cover under‑modeled regions quickly; supports continual learning without catastrophic forgetting.
In the robot: VBGS builds a probabilistic map of obstacles, articulated surfaces (drawers, fridge doors), and free space. The controller reads this map to plan paths and motions, assigning higher “costs” to occupied or risky regions. Because the map is Bayesian, where it designates high uncertainty, the policy that guides the robot shifts to conservative behavior (slow down, keep distance) or initiates “active sensing” for an information-gathering move like a brief re-scan or viewpoint change before committing to contact.
A Scalable Cognitive Core: AXIOM (Object‑Centric Active Inference)
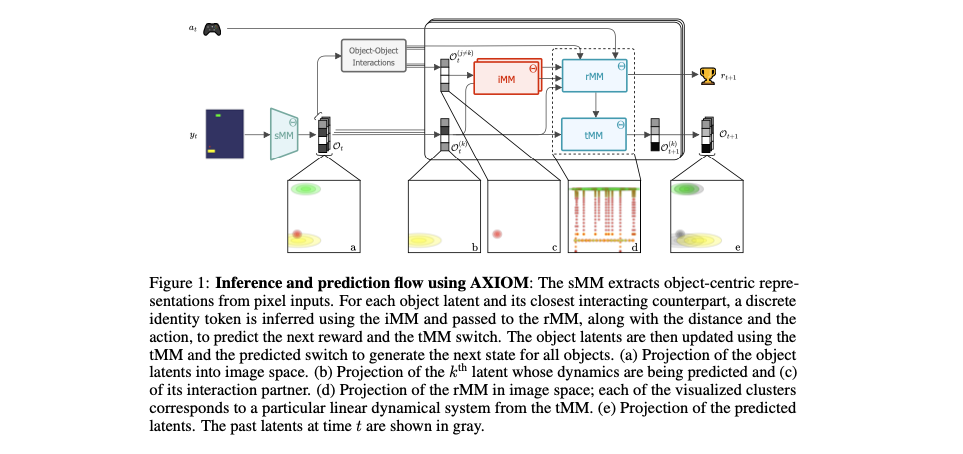
AXIOM complements embodied control with a world‑model and planning core that is fast, interpretable, and expandable:
sMM (slot mixture model): parses pixels into object‑centric latents (position, color, extent) via mixtures.
iMM (identity mixture): assigns type tokens (object identity) from continuous features; type‑conditioned dynamics generalize across instances.
tMM (transition mixture): switching linear dynamics (SLDS) discover motion primitives (falling, sliding, bouncing) shared across objects.
rMM (recurrent mixture): learns sparse interactions (collisions, rewards, actions) linking objects, actions, and mode switches.
Growth and Bayesian Model Reduction: expands components on‑the‑fly when data demands it; later merges redundant clusters to simplify and generalize.
Planning by expected free energy: trades off utility (reward) with information gain (learn what matters), choosing actions that both progress goals and reduce uncertainty.
AXIOM shows how Bayesian, object‑centric models learn useful dynamics in minutes (no gradients), clarifying how Active Inference can scale beyond low‑level control to task‑level understanding and planning, AND interoperate with human reasoning.
Why This Matters: Seamless Real-Time Adaptation
Since the system is built from agents that are themselves adaptive learners, the robot doesn’t need exhaustive pre-training for every possible variation. It can:
- Adapt on the Fly – If an object is heavier than expected, joint-level agents sense the strain and adjust grip force, while the high-level agent updates its belief about object weight for future handling.
- Recover from Failures – If a subtask fails (like dropping an item), the robot re-plans immediately without starting the whole task over.
- Plan Long-Horizon Tasks – The high-level planner can decompose a goal into subtasks dynamically, sequencing skills without having to learn every possible sequence in advance.
The Payoff: Habitat Robotic Benchmark Results (At‑a‑Glance)
Active Inference proves superior, adapting in real-time, with no offline training.
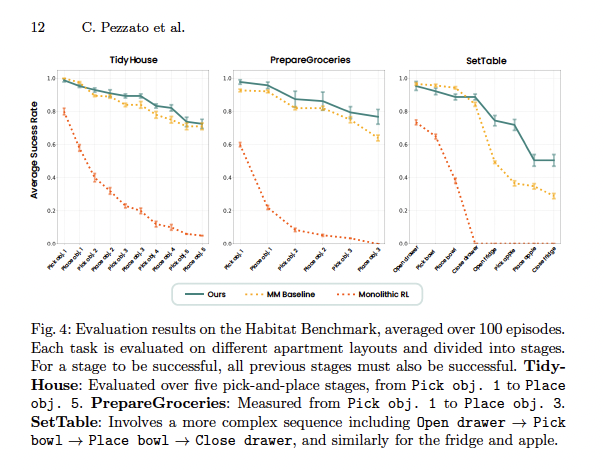
Benchmark Tasks (long‑horizon, mobile manipulation): “Tidy House”, “Prepare Groceries”, and “Set Table.”
Active Inference (AI) vs Reinforcement Learning (RL) baselines
Success/Completion (averaged over 100 episodes):
- Tidy House: 72.5% (AI) vs 71% (best RL multi‑skill baseline)
- Prepare Groceries: 77% (AI) vs 64% (RL)
- Set Table: 50% (AI) vs 29% (RL)
- Overall: 66.5% (AI) vs 54.7% (RL)
Training burden (baseline Reinforcement Learning): ~6,400 episodes per task + 100M steps per skill (7 skills) to train.
Active Inference: no offline training; hand‑tuned skills over a handful of episodes; adapts online (skills retry/compose autonomously).
Active Inference Adaptation: recovers from sub‑task failures by re‑planning (alternate approach directions, base repositioning) without retraining.
Significance: This is the first demonstration that a fully hierarchical Active Inference architecture can scale to modern, long‑horizon robotics benchmarks and outperform strong RL baselines on success and adaptability — without massive offline training.
From One Robot to Human–Machine Teams
Active Inference robots are uniquely suited to team up with humans. They reason in a way that is compatible with us, sharing a common sense-making framework: perceiving the environment, predicting outcomes, and adjusting actions to minimize uncertainty.

Here’s what that means in practice:
Safety through shared situational awareness: The robot can share its internal 3D “belief map” of the environment, including areas of uncertainty, with its human partner in real time. If it’s unsure whether a space is safe, that uncertainty becomes a joint decision point.
Safety through uncertainty management: The robot doesn’t just act; it calculates confidence. If confidence is low, it seeks input, pauses, or adapts, reducing risk.
Fluid division of labor: Just as two humans can read each other’s intentions and adjust roles dynamically, an Active Inference robot can anticipate when to lead, when to follow, and when to yield control for safety or efficiency.
Adaptive Role Switching: If a robot sees the human struggling with a task, it can take over — or vice versa — without a full reset.
In safety-critical domains like manufacturing, disaster response, or healthcare, this means a human and a robot can operate as true partners, each understanding, predicting, and adapting to the other’s actions without rigid scripting.

Human–Robot Collaboration Made Possible with Active Inference:
When both humans and robots operate on Active Inference principles, the synergy is remarkable. Here’s what happens when both parties have reasoning and logic capabilities:
- Mutual Predictive Modeling – Both can anticipate the other’s actions and adjust accordingly, leading to smoother collaboration.
- Shared Situational Awareness – Both track uncertainty, so they can signal when they need clarification or assistance.
- Context-aware negotiation: Decisions aren’t just made on what to do, but on why it’s the best action in the current context.
- Safety and efficiency: Logic lets both parties recognize when an action makes sense for the overall mission, not just their narrow role.
- Natural Task Division – Humans can handle high-level strategy while robots handle precise execution, each adapting in real time to the other’s inputs.
When one side doesn’t have that capacity, the reasoning partner must micromanage the non-reasoning partner, creating delays, errors, and frustration.
How This Scales to Teams, Cities, and the World: The Spatial Web (HSTP + HSML)
When you combine this internal multi-agent robotic structure with the Spatial Web Protocol, the collaboration scales beyond a single robot. This internal coordination becomes even more powerful through the HSTP and HSML. A team of robots (or a robot and a human) can operate as if they’re part of the same organism, with shared awareness of objectives, risks, and opportunities, so knowledge gained by one agent can inform all others.
HSTP (Hyperspace Transaction Protocol): Enables secure, decentralized exchange of belief/goal updates, constraints, and state updates between distributed agents — whether human, robot, or infrastructure. No central brain required.
HSML (Hyperspace Modeling Language): Gives all agents shared semantic 3D models of understanding of the environment/places, objects, tasks, and rules — so every agent reads the same plan the same way.
The result: The same belief propagation that coordinates a robot’s elbow and wheels can coordinate two robots, a human coordinator, and a smart facility, instantly and safely.
Imagine a hospital delivery robot, a nurse, and a smart inventory system -all operating as if they were parts of one coordinated organism, sharing the same mission context in real time. This level of cohesive interoperability across agents and platforms is one of the most profoundly beautiful aspects of this new technology stack.

Human–Machine Teaming in Practice
So what might this look like in the real world?
Aviation Ground Ops:
Current RL-driven robots require scripted contingencies for every deviation from plan.
An Active Inference robot spots a luggage cart blocking a service bay, predicts the delay’s ripple effects, and instantly negotiates a new task order with human supervisors — avoiding knock-on delays.
Disaster Response:
RL robots can detect hazards, but often lack the reasoning framework to weigh competing risks without retraining.
An Active Inference robot in a collapsed building senses structural instability, flags the uncertainty level, and suggests alternate search routes in collaboration with human responders.
Industrial Logistics:
In a smart factory, robots equipped with Active Inference and VBGS mapping adapt to new conveyor layouts without reprogramming, while humans focus on production priorities.
The Bigger Picture: AXIOM, VBGS, and the Spatial Web
VERSES’ broader research stack ties this directly into scalable, networked intelligence:
- AXIOM – A unified Active Inference model that works at every scale, from joint control to multi-agent coordination across networks.
- Variational Bayes Gaussian Splatting (VBGS) – An uncertainty-aware method for creating high-fidelity 3D maps of the environment, essential for safe, shared situational awareness in human–machine teams.
- Spatial Web Protocol (HSTP + HSML) – The data-sharing backbone that allows robots and humans to exchange spatially contextualized information securely and in real time.
Together, these form the technical bridge from a single robot as a teammate to globally networked, distributed intelligent systems, where every human, robot, and system can collaborate through a shared understanding of the world.
The levels of interoperability, optimization, cooperation, and co-regulation are unprecedented and staggering. Every industry will be touched by this technology. Smart cities all over the globe will come to life through this technology.
From "Tools" to Thinking Teammates
This isn’t just a robotics upgrade — it’s a paradigm shift.

Where RL robots are powerful but brittle tools, Active Inference robots are reasoning teammates capable of operating in the fluid, unpredictable reality of human environments.
This is happening right now, and it changes what we can expect from robotics forever.
You Can't "Un-See" This
VERSES AI’s remarkable work shows for the first time that a robot can evolve beyond the current Reinforcement Learning (RL) limitations:
- From per‑task brittle scripts to agents that can reason within themselves and adapt accordingly.
- From offline retraining to online inference and re‑planning in the moment.
- From opaque policies to interpretable, uncertainty‑aware world models (VBGS, AXIOM).
- And from “tools” to teammates who think with us.
This is the first public demonstration that Active Inference scales to real robotics complexity while outperforming current paradigms on efficiency, adaptability, and safety – without the data and maintenance burden of Reinforcement Learning.
It’s the first public proof that Active Inference can scale to the complexity of real-world tasks.
VERSES AI’s research stack resets the bar for what we should expect from robots in homes, hospitals, airports, factories, AND from the teams we build with them.
Want to learn more? Join me at AIX Learning Lab Central where you will find a series of executive training and the only advanced certification program available in this field. You’ll also discover an amazing education repository known as the Resource Locker — an exhaustive collection of the latest research papers, articles, video interviews, and more, all focused on Active Inference AI and Spatial Web Technologies.
Membership is FREE, and if you join now, you’ll receive a special welcome code for 30% all courses and certifications.

A dedicated space fostering an environment for learning, community, and collaboration around Active Inference AI, HSTP, HSML, and the convergence of technologies utilizing these new tools – Digital Twins, Robotics, IoT, Smart Cities, Smart Technologies, etc…
The global education hub where our community thrives!
Scale the learning experience beyond content and cut out the noise in our hyper-focused engaging environment to innovate with others around the world.
Join the conversation every month for Learning Lab LIVE!