A first-hand account of the 12 days leading up to the official launch.
On March 13, 2026, we opened the ARC-AGI 3 developer toolkit for the first time. The toolkit, released on January 29, 2026, connects and integrates agents to the games through their API with a user interface designed for transparent evaluation.
ARC-AGI developer toolkit release date
At that point, this looked like what many of us in AI have been waiting for — a serious attempt to move beyond static benchmarks and into something closer to real intelligence — interactive, novel environments, and compositional reasoning. Requiring systems that have to explore, act, adapt, and figure things out on the fly in real time.
Perfect! That’s exactly the direction AI needs to go, and the type of evaluation necessary to determine an agent’s ability to truly reason and learn.
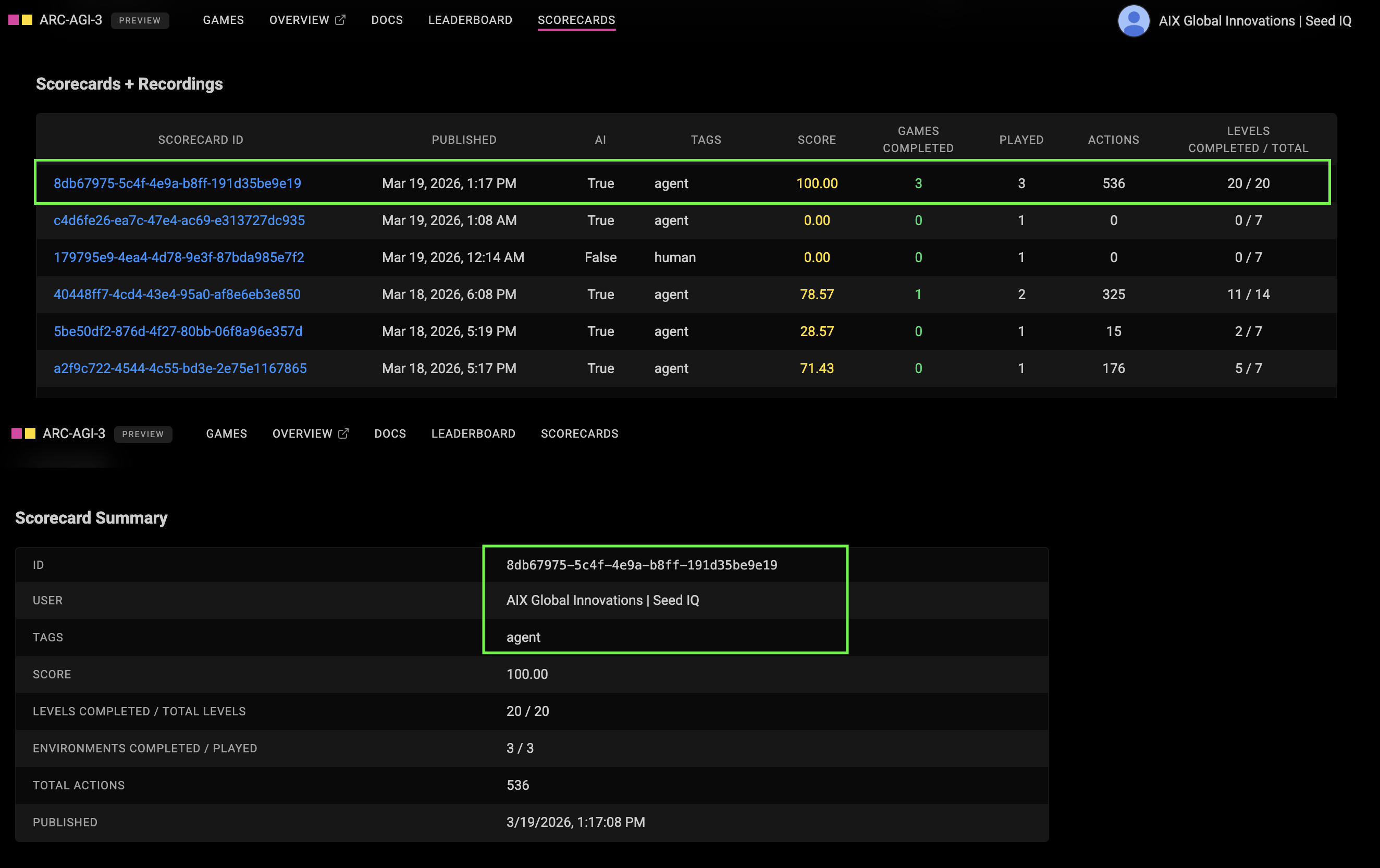
My Co-Founder and Chief Innovations Officer, Denis O, started playing around with the ARC 3 developer toolkit on March 13th, connecting our Seed IQ™ — the first Active Inference autonomy engine, an agent architecture for adaptive multi agent autonomous control over complex systems. (Prior to the official ARC-AGI 3 launch last Wednesday, there were 3 games available to play: LS20, VC33, and FT09.)
Two days later — March 15th — we had already solved all three of the available games — at top human-level performance.
100% across all 3 games.
20 out of 20 levels.
536 total actions.
ARC-AGI 3 unverified LIVE leaderboard on March 15, 2026 displaying AIX Global Innovations' Seed IQ placing 4th under the top three human scores.
That result placed us just below the top three human scores on the unverified leaderboard. All three humans had a tied score of 528.
And that’s when things started to get… interesting.
The First Sign Something Wasn't Right
We were also listed on the human leaderboard.
That didn’t make sense.
We were interacting with the games through the ARC Prize API and UI. Their system clearly recognized us on the scorecards as an agent through the API integration. There was no ambiguity in how the system was being run. And yet, our score was landing us on the human leaderboard. Could it be because of the score?
Slack conversation showing Denis of AIX sending Denise official proof of "agent" status from ARC Prize API scorecards.
Screenshot showing our internal ID for AIX/Seed IQ within the ARC 3 API matches with the scorecard ID, identified as an agent, with our top human-level score.
We weren’t sure what to make of it.
But it was the first indication that what was being displayed publicly didn’t fully match what was actually happening behind the scenes.
Then Greg Reached Out
On March 16, Greg Kamradt from the ARC Prize Foundation emailed Denis directly.
He introduced himself and asked a simple question:
Email from Greg Kamradt of ARC Prize to Denis at AIX Global Innovations.
“How is it going so far? What’s your interest in trying it out?”
It wasn’t framed as an invitation to participate formally. It was an inquiry into how our experience was going and why we were playing.
Denis responded thoughtfully, explaining that what we are building with Seed IQ™ is fundamentally different from typical deep learning systems. That our system is built on Active Inference and physics driven dynamics. It operates through adaptive, multiagent autonomous control (AMAC) where agents maintain and update structured beliefs about the environment in real time through “adaptive, stateful control and coordinated planning,” rather than relying on pattern matching or training-based inference.
We also made something very clear from the outset.
“We are a serious contender here, but we operate with a proprietary patent-pending tech stack, so we cannot participate in any setup that requires exposing source code or internal implementation details.” — Denis O.
So we proposed an alternative…
A sealed or remote evaluation setup where:
we submit outputs or run remotely
our code remains private
results are verifiable on their side
The response we received from Greg was straightforward: that option didn’t currently exist.
In the meantime, our very strange position on the “human” leaderboard was shifting. Other entries were suddenly appearing above us with better scores that were dated weeks prior to us. Yet, they weren’t showing on this leaderboard in the first few days of us playing the games. It was like entries were suddenly being added.
Image showing AIX was also being listed on the "Human" leaderboard
I followed up with Greg again on March 20, reiterating our position and asking if there was any way to accommodate a secure evaluation path that would protect proprietary systems so that we could participate officially after the launch.
We made it explicitly clear that we were willing to forego prize money entirely to make this work.
We haven’t received a response since.
And Then Everything Changed
The next day — March 21 — Denis called me…
And the first thing he said was:
“I think we may have triggered them.”
One of the three games — LS20 — was significantly different. What he was seeing was not a minor adjustment. They increased the complexity of this game dramatically.
As Denis described it:
“They didn’t just introduce new elements… they changed the game dynamics themselves.”
And then, more bluntly:
“They didn’t just take it up a notch. They went… nuclear.”
Before and after of in-game elements on the LS20 ARC 3 game after the difficulty increase on March 21, 2026.
New mechanics were introduced. Constraints that didn’t exist before suddenly mattered. They introduced carryover constraints. If you were inefficient in early levels, it now impacted your ability to complete later ones. You could lose lives. New dynamic elements were introduced that forced an agent’s continuous re-computation of strategy at every step.
Before the change, the agent was the only entity moving through the environment. After the change, you had blue “pushers” that would push you as you were exploring the environment, and the “sprites” now moved around like Snitches in Harry Potter. The entire environment became alive with dynamic activity, and the game objectives shifted dramatically.
This fundamentally changed what the benchmark was testing.
And, importantly… it happened quietly.
There was no announcement. No update. No explanation. No indication on the leaderboard. All these changes took place quietly behind the scenes.
Screenshot of the Toolkit Changelog from March 24th that shows no announcement had been made regarding the increased complexity and changed game dynamics.
What Made This Even More Strange
The verified leaderboard didn’t change after that. There was no update to reflect that those scores were achieved prior to this substantial change.
It continued to display results from the previous version of the benchmark — the original, lower-complexity environment.
Prior to the complexity change of LS20, one of the ARC Prize test agents, Stochastic Goose, had scored 12.58% across 2 games with 255,000 actions (the highest score on the leaderboard of any other agent.) With most other agents’ high scores at 2%-8%.
Yet, the unverified leaderboard only had two entries now, and they were clearly playing against the new game dynamics, recognized by the sudden drop in score and game playability.
ARC-AGI 3 Verified and Unverified Leaderboards on March 21, 2026 after complexity increase on LS20 game.
The human leaderboard didn’t display a change until the next day, on March 22nd. All of a sudden, all previous scores had been removed, and the new scores showed that humans were now struggling to complete all 3 games. And something else was happening that was strange… many of the entries being shown now had no names attached to them.
ARC-AGI 3 Human leaderboard on March 22, 2026, now reflecting humans having difficulty solving all three games.
So for several days (from March 21–25), there were effectively three different realities to anyone playing these games:
The environment we were actually solving (new complexity and dynamics)
The internal benchmark conditions (already changed)
The public leaderboard (still showing old results for verified scores, but the unverified and human leaderboards were telling a different story)
Those layers were not aligned.
A few thoughts came to mind during this time. Did we catch the ARC Prize folks by surprise by achieving perfect scores across all three games just prior to launch, and was the sudden change in complexity related to that? Or were they simply making changes to prepare for the launch that was five days out? Were they planning to wipe the leaderboards clean, so it didn’t matter what they displayed anymore in the days leading up to the launch?
Denise and Denis O of AIX discussing the unfolding situation through Slack on March 24th, the day before the launch.
There were a lot of questions. It was a fascinating unfolding of events — especially because it was a LIVE, unfolding demonstration of how agent systems and people react to sudden change and increased difficulty.
During that time, we continued testing with the new dynamics.
What Happened to All Other Agents?
Before the changes, there were other agents placing on the verified and unverified leaderboards. These were deep learning approaches/reinforcement learning systems. Variants of what most of the industry is currently building as agents.
Prior to the increase in complexity in the LS20 game, those systems were struggling to solve the games, with only a few solving one or more games, but most were still scoring between 2%-8%. After the change, those systems collapsed. Completely.
ARC 3 verified AI Agent leaderboard scores prior to the game changes.
The ARC team’s own highest-performing test agent, Stochastic Goose — which had previously achieved 12.58% across two of the games with 255,964 actions — dropped to 0.25% on the new official leaderboard when ARC-AGI 3 officially launched mid-day on March 25th. This new score reflected this agent’s ability to score when faced with the new complexity of LS20. (The new official leaderboard does not reveal actions or levels completed anymore, only the score.) And you can see this score was achieved 18 hours prior to the official launch, so effectively on March 24th.
Screenshot of the ARC-AGI 3 new official leaderboard unveiled at launch time of March 25, 2026 displaying their own three test agents with a highest score of 0.25%, tested approximately 18 hours prior to launch on March 24th.
Other agents that had been scoring between 2% and 8% before the increased complexity, also effectively fell to zero.
As of this writing and since the official launch on March 25th, no agent has been able to exceed 0.50%.
ARC 3 official leaderboard as of March 29, 2026 displaying a highest score of 0.50%.
That is not a small drop in performance.
That is a complete breakdown… a structural failure in agent performance.
The other interesting thing I noticed is that since the launch, the website prompts you to begin with the LS20 game (the one they dramatically increased the difficulty on), even though you can choose to play other games. As of this writing, we have not attempted any of the other new games, yet.
Game LS20 displays first on the website to begin playing.
How Did this Change Affect Seed IQ's Performance?
We solved LS20 again, using far less actions than it states is the human baseline to solve the game. The human baseline for LS20 is 546 actions, Seed IQ™ solved it in 433 actions with a score of 86.46% for that game — solved under the increased complexity and new game dynamics.
Again, Seed IQ™ solved all 3 games. All 20 levels.
95% overall score. 681 actions across all 3 games
AIX's Seed IQ ARC 3 official scorecard demonstrating new human-level results after the game dynamics and complexity was significantly increased.
Seed IQ exceeded human performance requirements for the other two games.
If you look at the Human baseline for the VC33 game (screenshots below), the ARC Prize website states a baseline of 307 actions for human-level performance. On our scorecard (above), you can see that Seed IQ™ completed it with far fewer actions — 173 — with a perfect score of 100%.
The Human baseline for FT09 is 163 actions, and Seed IQ™ solved it with just 75 actions and another 100% perfect score.
Screenshots displaying the ARC-AGI 3 Human baselines for games VC33 and FT09 after official launch.
Even after the increase in complexity, uncertainty, and surprise introduced during LIVE gameplay, Seed IQ™ proved to still operate at top human-level performance on all 3 games.
So, How is Seed IQ™ Performing So Differently Than Every Other Agent?
Before we get into the rest of how this story unfolds, let’s talk for a minute about how Seed IQ™ is achieving these scores…
Seed IQ™ is not a deep learning / reinforcement learning (DL/RL) system. No super-powered GPUs are required to run it. It is a low cost, efficient alternative to the current AI paradigm.
Seed IQ™ (Intelligence + Quantum)coordinates action, drives operational coherence, and adapts continuously across complex environments. Built on the principles of Active Inference, physics driven dynamics, and decentralized multi agent control to enable what we call, Adaptive Multiagent Autonomous Control (AMAC), turning any operational environment into a continuously adaptive, self-coordinating, self-regulating system. This is not a prediction engine, and not an optimization heuristic. It works at the level of real-time execution, governing how complex systems behave over time by coordinating multiple agents that learn, plan, adapt, and act locally while remaining coherent at the system level.
https://aix.us.com
Seed IQ™ enables fully autonomous multi agent reasoning through bounded autonomy and ever-evolving world models, occupying a solution-space that current AI approaches cannot reach, one where intelligence is measured by how well it governs execution under uncertainty, contains failure before it cascades, and preserves coherence as systems scale.
There is no human-in-the-loop enabling adaptation. This is operationalized multi agent Active Inference.
Seed IQ Technical Reports on VQE and Barren Plateaus and QEC. - https://aix.us.com/quantum-computing
What This Reveals About Current AI - DL / RL Systems
What we observed in these days leading up to the launch was not just a stark difference in results.
It was an unfolding real time demonstration in how systems behave under pressure through increased complexity and uncertainty.
Deep learning systems depend on prior data, learned patterns, and learned representations/stable structures. When those structures change in ways they haven’t seen before, performance doesn’t degrade gradually.
ARC-AGI 3 is built on a very specific premise: These are games that are easy for humans, but difficult for AI, and that premise depends entirely on the validity of a human baseline.
On launch day, Francois Chollet, Founder of ARC Prize emphasized that they had conducted extensive human testing and that all environments were 100% solvable by humans on first contact.
Francois Chollet, Founder of ARC Prize, announces the official launch of ARC-AGI 3 on March 25, 2026.
Yet, the final version of the LS20 benchmark game, the one being evaluated, had only existed in its updated form for a very short window of time.
And this is important because five days before launch, the complexity and game dynamics completely changed, and human exposure to that updated environment only existed for a few days. After the change, we were seeing a significant change in performance on the human leaderboard in the days leading up to the launch.
Something else I observed the day before the launch (shown in this screenshot):
ARC 3 Human Leaderboard on March 24th, 2026, the day before the official launch, demonstrating humans struggling to perform well on LS20 after the increased complexity.
On March 24th, the day before the launch, the human leaderboard displayed for the first time one player who clearly had access to more than the 3 initial games. This player suddenly had completed 25 games, but no one else was listed as completing more than 3. This raises the question on the additional newly launched games used in the benchmark for ARC 3. How was a human baseline established for these games to come to the conclusion that they are all 100% solvable for humans?
That distinction matters.
Because the meaning of “human-level performance” depends entirely on the stability of that baseline.
This previous screenshot also displays that the rest of the “human” players in the 24 hours leading up to the launch —players that were subjected to the increased complexity and new game dynamics, particularly for LS20 (the game that was altered significantly), there were now only 12 humans who could solve all 3 games. And the best human score was 551 for those 3 games, and only four humans scored a perfect 100. Clearly this change in game dynamics affected the humans’ ability to solve that third game (LS20). Further, 100% seems to be the “top-level” human performance, not “normal” human performance.
So, if you examine Seed IQ’s score under the increased complexity where we scored 95% with 681 actions across all 3 games, and compare that with the actions of the top humans playing those same 3 games after the changes. There were only three humans with fewer actions than Seed IQ™ (551, 554, 634). The 4th human scored 100% with 1016 actions.
ARC 3 human leaderboard showing the best human performance under the new complexity, compared to our new scores just prior to the official launch. Seed IQ is still maintaining top human-level performance.
Seed IQ™ clearly still maintained top human-level performance even after the increased complexity, fully adaptive under uncertainty, achieving a score that placed it within the leading 5 humans competing on ARC 3 at launch time on the March 25th.
The Participation Problem
There is another important issue here that shouldn’t be ignored, and it begs the question, what exactly is ARC-AGI 3 benchmarking?
Under the current rules, “official” participation in ARC-AGI 3 requires:
full codebase submission
detailed methodology disclosure
reproducibility sufficient for others to replicate the system
And under those terms, the rules specifically state that submitted work can be used commercially with no limits by anyone beyond the competition.
ARC Prize ARC-AGI 3 official rules stating that participants must give all code and commercial rights to the contest.
For much of the deep learning community, this is not a barrier. These systems are all built on the same foundation models and open frameworks. If this benchmark is highlighting anything, it is that DL systems have no moat. And not surprisingly, they are all performing more or less equally on ARC 3 — essentially at zero.
But for systems that are truly proprietary — systems designed for real-world commercial deployment — this requirement bars them from participation. No one with truly proprietary IP in a trillion-dollar industry is going to give away their IP for the sake of a contest. The notion of that is ridiculous.
We made it clear from the beginning that is something we cannot do.
We asked for a secure evaluation pathway. We offered to participate without prize incentives. We received no viable option or pathway to be able to be included in this “benchmark.”
Which raises an important question:
If the most advanced systems cannot participate without giving up their IP… what exactly is the benchmark measuring?
There is also a broader context that is worth acknowledging…
Francois Chollet's AI company, Ndea, raised $40M+ in recent funding, positioned as a lab to pursue AGI.
One of the ARC Prize founders, François Chollet, has recently raised $40M+ as a co-founder of an AI lab, Ndea, focused on Artificial General Intelligence (AGI). At the same time, ARC-AGI 3 is positioning itself as a pinnacle central benchmark in the AI industry with a purported mission to evaluate the most advanced AI systems — while requiring participants to submit their full codebases, methodologies, and implementation details under terms that allow for reuse and commercialization.
That dynamic is important for the broader AI community to understand.
This is not to suggest intent, but it does raise a reasonable question around incentives, participation, and alignment. If an industry “benchmark” becomes a central point of aggregation for the IP of novel AI approaches — particularly under conditions that require full transparency and transferability — then it is worth asking how that structure impacts which systems participate, which ones do not, and what ultimately gets represented as “state of the art.”
What This Experience Actually Shows
Over the course of 12 days, we observed:
A benchmark that changed materially during pre-launch testing, without announcement or notice to the players
A leaderboard that did not reflect those changes in real time
A leaderboard that displayed inconsistent and inaccurate information
A human baseline that was intended to be established over months of human gameplay, but was redefined over the course of a few days, just prior to launch, after serious changes were made to game dynamics and mechanics, with complexity increased dramatically.
A major collapse in performance from deep learning agent systems after those changes were made, under the newly increased complexity — effectively making the games impossible for them to solve just prior to the launch.
And one system — Seed IQ™ — that continued to adapt and perform and solve all three available games with results that fall into the top 5 of human-level performance. Even more impressive, Seed IQ achieved this using a Macbook Pro M1 laptop. No super-powered GPUs, no token expense, no checking in with the mothership to process queries.
This article is not an attempt to diminish what ARC-AGI 3 is doing. And the founders have every right to keep the competition aimed at the open-source community. But then the benchmark’s value and the conversation around what it is measuring materially shifts.
A benchmark that is positioning itself as “The North Star of AGI” to judge the best of AI — further, AI that indicates general or human-level intelligence — becomes largely meaningless to the wider AI community if the most novel, innovative, and proprietary systems are not being included in the official results. Additionally, what does it say when a “benchmark” only targets a sector of the industry that can’t seem to score at all?
ARC-AGI 3 Official Leaderboard displaying the enormous cost involved in foundation models participating and effectively scoring zero in the competition.
In many ways, all of this is pushing the conversation in the right direction. ARC 3 is revealing the truth about DL / RL systems.
And regardless of benchmark rules for “official” participation vs. participating by independently interacting with the games through the ARC Prize API on your own, ARC-AGI 3 is demonstrating something very clearly:
The future of AI will be determined by which systems can adapt on the fly as the environment changes and unfolds in real time. And that is the most important distinction that fulfills the ARC Prize founders’ objective with ARC 3.
Final Thoughts
We didn’t go into this expecting to make a statement.
We were just having fun testing our system, Seed IQ™, against other agent systems, along with seeing how we compared to human performance.
But what unfolded over those days leading up to the launch reveals a lot, and it opens up questions about this particular benchmark and the state of AI today.
If ARC Prize is positioning itself as a judge of the best of AI, then why are proprietary systems excluded from participation?
ARC 3 appears instead to be a competition geared for DL / RL systems (ones that have no moat and no proprietary code). In that respect, it becomes less of a benchmark to identify and spotlight the innovative AI systems that actually do possess the ability to reason, plan, and adapt in real time, and by default becomes an open proving ground that DL/RL does not possess true reasoning and has no ability to adapt to novel environments in real time (effectively scoring zero in complex adaptive environments), while costing thousands of dollars each to prove it. We all knew that was the case already, but this is demonstrating proof of it on a public stage.
“We are not claiming AGI with Seed IQ™, despite its performance on ARC-AGI. What we are saying is more precise. There is a path to adaptive intelligence that does not rely on deep learning, reinforcement learning, LLMs, or even classical active inference as it is typically framed today. That path is grounded in superior mathematics, in first principles, and in physical dynamics, where coherence and stability are intrinsic to the system rather than imposed from the outside. In that framing, intelligence is not about reward optimization or statistical pattern fitting, but about maintaining a viable and coherent structure under uncertainty. Seed IQ™ points in that direction, showing that adaptive AI can remain stable, coherent, and explainable when it is built on the right foundations rather than scaled approximations.” — Denis O
https://aix.us.com/
If you want to see Seed IQ™ in action on the first three ARC 3 games, we’ve shared a walkthrough demonstrating how it operates under increased complexity here:
We’ll continue evaluating ARC-AGI 3 independently and remain open to official participation under conditions that preserve proprietary systems.
If you’re building the future of energy systems, quantum infrastructure, logistics, supply chains, manufacturing, finance, or robotics, this is where the conversation begins.
A dedicated space fostering an environment for learning, community, and collaboration around Active Inference AI, Seed IQ™, Spatial AI, HSTP, HSML, and the convergence of technologies utilizing these new tools – Digital Twins, IoT, Smart Cities, Smart Technologies, etc…